Back to the audio resources page
A Sector-Based, Frequency Domain Approach to Detection and Localization of Multiple Speakers
G. Lathoud and others
This webpage describes the 16 kHz multichannel data used for experiments in the paper with
same title, submitted to ICASSP 2005.
Pointers to DIVX videos and WAV sound files are included.
Questions? -> 
Note: optimized C code can be accessed here.
Online Access to Audio and Video Recordings
Sequences were taken from the AV16.3 corpus [2]:
Seq. #1, #2 and #3: loudspeaker recordings (emitted signals and recorded signals) can be accessed here (WAV files).
Seq. #4: this single human speaker sequence can be accessed here, including a DIVX file and a WAV file.
Seq. #5: this 3-human speaker sequence can be accessed here, including image snapshots 1, 2, 3 and a WAV file
Important Note on Ground-Truth Annotation
-
In the loudspeaker case (Seq. #1, #2 and #3), precise
speech/silence ground-truth (GT) segmentations and true 3D locations
are known by construction.
- In the human case (Seq. #4 and #5),
speech/silence GT segmentations were provided by a human listener. We
took particular care not to miss any speech in the GT
segmentation, therefore GT speech segments often include silences -
e.g. a pause between two words. 3D location truth was provided with a
3D error (1.2 cm) negligible compared to the mouth size, from
calibrated sameras [2].
Description of the Data
Real recordings were made in an instrumented meeting room [1] with a horizontal circular 8-mic array (10 cm
radius) set on a table. The data is part of AV16.3, a larger corpus available online [2]. Each source was annotated in terms of both
spatial location and speech/silence segmentation. In this paper,
given the microphone array's geometry, source location is defined in
terms of azimuth. Time frames are 32 ms long, with 16 ms overlap. We
used 5 recordings from the AV16.3 corpus [2]. In all cases, a circular, 8-microphone array
with radius 10 cm was used.
- Seq. #1 (20 minutes): it is named "synthmultisource-setup1" in the AV16.3 corpus [2]. 3 loudspeakers at equal distance (0.8 m) of the
microphone array were recorded playing 20 minutes of synthetic speech
with equal power, as an alternation of 4 seconds of stationary vowel
sound followed by 2 seconds of silence. In each sequence, all 200
possible combinations of 2 and 3 active loudspeakers and 5 different
vowels are played sequentially. Vowels are synthesized using a LPC
vocoder and constant LPC coefficients, estimated from real speech.
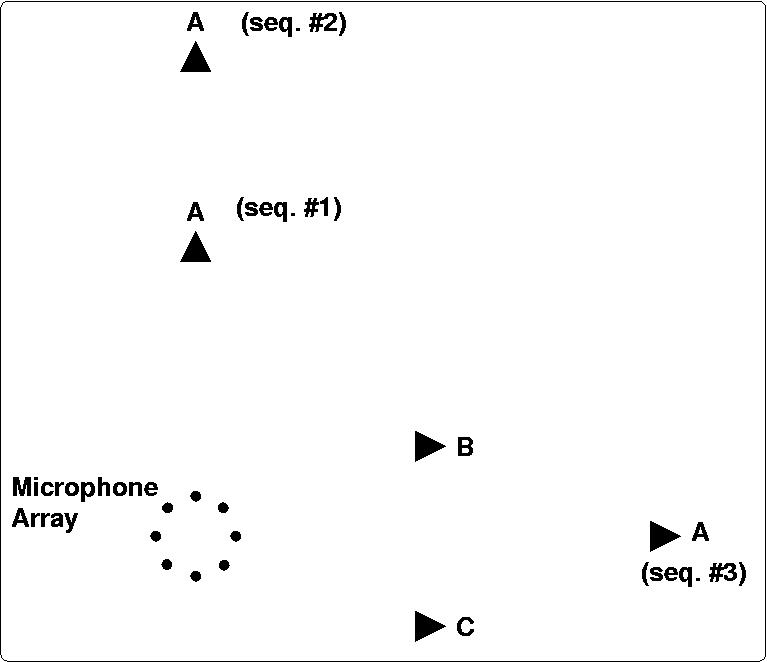
Figure 1 below shows the setup of the three loudspeakers.
- Seq. #2 (20 minutes): same as Seq. #1, but loudspeaker A is placed at
1.8~m from the array, to test if the proposed method works with one
source being much further than the others.
- Seq. #3 (20 minutes): same as Seq. #1, but loudspeaker A is placed at
1.45~m from the array, in the middle direction between B and C. This
tests whether the proposed approach can deal with a larger distance
for A and lower angular separation.
Figure 1: Top view of the experimental setup for Seq. #1, #2 and #3: 3 loudspeakers A,B,C. Loudspeaker A lies at 90 degrees relative to the array in Seq. #1 and #2, and at azimuth 0 degree in Seq. #3. Loudspeakers B and C lie respectively at +25.6 degrees and -25.6 degrees in all three sequences.
- Seq. #4 (3 minutes 40 s): A single human speaker is
recorded at each of 16 locations, covering an area that includes the
five locations depicted in Figure 3 below. Precisely, this area spans 121
degrees of azimuth and radius 0.7 m to 2.36 m, relative to the array.
Figure 2: Snapshot of the single speaker recording (Seq. #4), at one of the 16 locations.

- Seq. #5 (8 minutes 30 s): three human speakers, static
while speaking. Speaker A spoke at three different locations A1, A2,
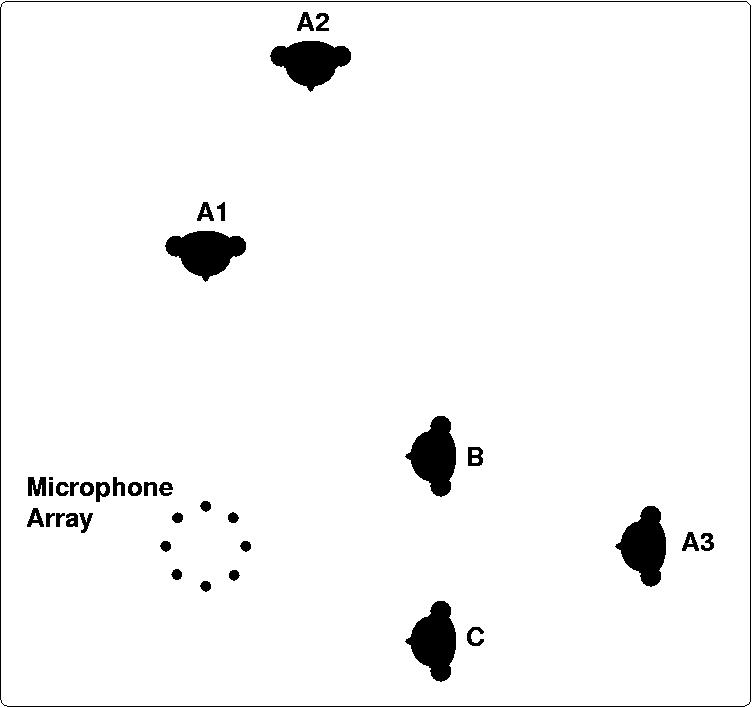
A3. Figure 2 below shows the persons' locations.
Figure 3: Top view of experimental setup for Seq. #5: three persons A,B,C. Person A speaks successively from 3 different locations A1, A2 and A3.
References
[1] D. Moore, "The IDIAP Smart Meeting Room", IDIAP-COM 02-07, IDIAP, 2002 (ps, pdf).
[2] G. Lathoud, J.M. Odobez and D. Gatica-Perez, "AV16.3: An Audio-Visual Corpus for Speaker Localization and Tracking", in Proceedings of the MLMI'04 workshop, 2005 (ps, pdf).
Back to the audio resources page
Last updated on 2008-09-03 by Guillaume Lathoud - glathoud at yahoo dot fr